
Pasando de CPU a GPU

Buenas a todos de nuevo! En mi último artículos os hablé sobre los TextureAtlas y su utilidad a la hora de trabajar con OpenGL.
Existe una faceta de Brakeza3D, que no he tenido tiempo de reflejar en artículos y es toda la teoría de optimización aplicada en este último año: desde la programación multihilo, la rasterización por tiles, el oclussion culling y un largo etc, que iré desarrollando en artículos futuros donde explicaré todas estas técnicas y cómo implementarlas desde cero.
Con todo este proceso de optimización he conseguido un resultado muy satisfactorio. En la actualidad consigo una tasa de 60fps estables (mapas viejos quake1, 2, y 3 a 640×480), pero la realidad es muy tozuda y han surgido algunos inconvenientes que me han hecho replantearme el añadir finalmente la feature de render por GPU en Brakeza3D.
Mi caso personal es que estoy desarrollando un juego 3D old-school a 320×240, voy sobrado, pero son varios los programadores que han hecho pruebas con modelos modernos y me han trasladado la lentitud del render. Analicemos el motivo.
La realidad
Como os podéis imaginar, un único modelo 3D moderno, pongamos de un NPC “genérico”, tiene más polígonos que todo un mapa de un videojuego de los años 2000 (el doble o el triple!). Para que os hagáis una idea un modelo de personaje de Quake3, rondan 1K de triángulos, un modelo gratuito de mixamo.com (Adobe) puede superar los 40K. La diferencia es demasiado grande.
El talón de Aquiles de un render CPU vendrá determinado por 2 factores principales: El número de triángulos y la resolución. Aunque el número de triángulos obviamente influye, un render CPU sufre estrepitósamente al renderizar escenas con alta resolución, ya que hay más pixeles que procesar, suena lógico. Todo ello se complicaba si quería mantener algunas características tipo iluminación dinámica, por no hablar de las sombras dinámicas, ambas features con un consumo dramático de CPU.
En general, cualquier modelador/diseñador/artista 3D moderno, suele utilizar más triángulos de los que se pueden mover con comodidad por CPU. El trabajar para un motor antiguo en muchas ocasiones entorpece el proceso, ya que hay que generar versiones LOW-POLY de los modelos existentes, y esto a veces, no es trivial, cuesta mucho tiempo o en su defecto dinero. (no siempre sirve usar un decimate para reducir geometría…)
Por todas estas razones y si quiero que algún día Brakeza3D sea utilizado por algún estudio Indie para cualquier proyecto, se hace inevitable meter más chicha al render.
OpenCL
En el fondo, ya hace mucho que Brakeza3D dispone la feature de render por GPU. Los valientes que se hayan atrevido a ojear el código habrán reparado en un fichero:
https://github.com/rzeronte/brakeza3d/blob/master/opencl.cl
Se trata de un rasterizador completo hecho con OpenCL en menos de 700 líneas. Es un kernel monolítico que incluye todo el proceso de render en un único fichero.
En el fondo, fue más un experimento personal mientras me leía un par de libros basados en esta tecnología, la cual es fantástica, tengo que añadir. Como podéis imaginar el resultado de OpenCL era infinitamente más rápido que el render CPU (y mucho más del render que yo disponiá en aquel momento, sin optimizar).
En su momento decidí no avanzar en la línea de un rasterizador con OpenCL, tecnología estupenda para científicos y “gente que necesite” cálculos masivos con GPU, sin tener q ceñirse a un enfoque 3D como tenían que hacer hasta entonces. Tenía claro que si quería avanzar con la GPU lo haría con OpenGL o Vulkan, pero no era mi objetivo y quedó paralizado hasta hace un par de meses.
Implementacion con OpenGL
Tengo que decir que cuando empecé a migrar Brakeza3D a OpenGL me llevé una buena sorpresa al averiguar que todo mi knowledge sobre OpenGL estaba más que muerto y enterrado. Habían pasado unos 15 años desde mis últimos experimentos con OpenGL, el “modo inmediato” había quedado obsoleto (adiós glBegin/glEnd)
Hubiera sido relativamente trivial convertir el render de CPU a GPU con openGL en modo inmediato. Pero.. ¿Que demonios es el modo inmediato?: Un render en modo inmediato es aquel que una vez hace los cálculos para un triángulo, lo tira directamente a la salida. En definitiva hubiera sido un pequeño cambio en el código, donde antes rasterizaba un triángulo por CPU, ahora lo haría por GPU, más o menos sencillo.
Asi funcionan centenares de videojuegos existentes, sin ir más lejos el QuakeGL, funciona así, OpenGL antiguo en modo inmediato. Todos los juegos que conocéis hasta el 2004 aproximadamente funcionan así.
El problema es que YA hace mucho tiempo que este enfoque quedó deprecado en OpenGL y aunque hay formas de seguir trabajando con este sistema, es una forma muy primitiva de trabajar con gráficos en 3D, por todas las desventajas finales que existen.
Tocaba ponerse las pilas en OpengGL moderno: VBOs, VAOs, IBOs, pero lo más importantes de todo, los Shaders (los cuales me tienen enamorado).
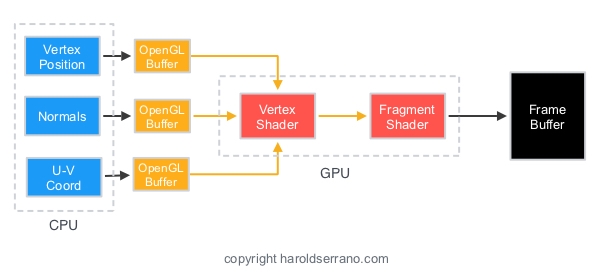
El gran problema, es que al no poder usar el modo inmediato, tenía que realizar modificaciones de calado en el código. Principalmente reorganizar la información de los vértices.
En OpenGL moderno los vértices de los modelos se agrupan en “Vertex Buffer Objets”, que no es más que un array con todos los vértices de dicho objeto y que podemos enviar a la GPU en un único paso. Esto sería lo ideal siempre, si puedes dibujar TODA tu escena de una tirada, adelante!. Por ejemplo Doom3, solo realiza una única drawcall por frame, brutal!.
No siempre es trivial organizar tu información en una única “draw call” que así es como se llaman. Un mismo objeto 3D puede estar formado por una o varias texturas, esta información también ha de ser tenida en cuenta.
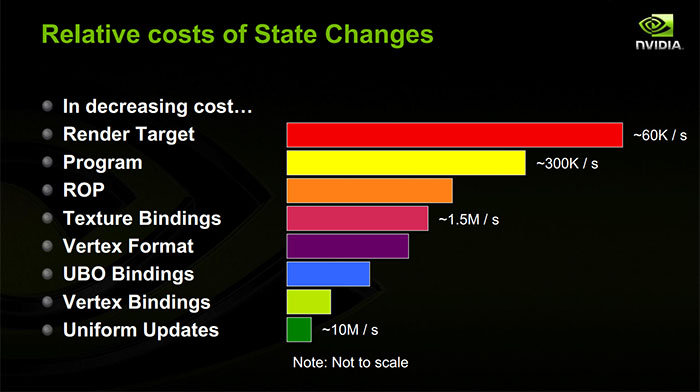
En la imagen superior podéis haceros una idea de las operaciones más costosas en OpenGL, se puede observar como los texture bindings tienen un coste notable. Por esta razon hemos de evitar cambiar el estado de la textura salvo que sea realmente necesario.
OpenGL dispone de mecanismos para trabajar en un Shader con varias texturas, es cierto, pero de una forma muy limitada. Por ejemplo existen los TextureArrays, pero deben tener todas sus texturas el mismo tamaño y también se pueden enviar texturas manualmente al shader, pero… ¿y si no sabes exactamente cuantas texturas tendrá tu modelo?, si tiene 40 texturas, no vas a preparar 40 variables para enviar al Shader.
Ya os estaréis imaginando que éste fue el motivo por el que implementé el TextureAtlas, para poder enviar todas las texturas al shader en un único paso, sin cambios de estado. No obstante, una opción muy común en OpenGL moderno es renderizar por lotes la geometría que comparte la misma textura, con esto evitamos estar constantemente cambiando el estado de OpenGL para modificar la textura de turno.
Pongamos un ejemplo: dispongo de un mapa, el cual tienes muchas texturas. Imaginemos que todas las paredes usan la misma textura, procuraremos enviarle a la GPU todas las paredes en una única “draw call”, así sucesivamente por cada textura/material.
Por todas estas cuestiones es importante organizar el cómo envías la geometría a OpenGL, si quieres obtener buenos resultados. Evitando realizar drawcalls innecesarias.
Así que fuí extendiendo cada objeto 3D en brakeza para disponer de sus VBOs organizados por texturas en todos aquellos sitios donde usar un TextureAtlas era contraproducente. Por ejemplo tiene sentido crear un TextureAtlas para renderizar todo un mapa BSP, donde existen muchísimas texturas (indeterminadas), ya que habría cientos de cambios de estado en la textura de OpenGL. De hecho un mapa BSP tiene una textura de lightmapping POR CADA triángulo, asi que implicaría un cambio de textura por cada uno, un suicidio en términos de rendimiento.
Sin embargo, para un simple modelo de un personaje, podemos permitirnos el lujo de dibujarlo en más de una drawcall por cada textura, ya que apenas tendrá unas cuantas.
En la actualidad cualquier objeto3D en Brakeza3D dispone de un método “OpenGLInitVBO”, el cual se encarga de preparar esta información en fase de carga, para disponer de esta información cada frame.
Shaders
Como adelantaba arriba, uno de los cambios más importantes en la pipeline del OpenGL moderno (aunque ya hace años de esto), es el uso obligado de SHADERS, concretamente dos: VertexShader y FragmentShader.
Un shader no es más que un programa que se ejecutará en la GPU que nos permite realizar operaciones sobre la información que se le envía. Se implementan en un lenguaje propio llamado GLSL, el cual es muy similar a C. Podemos implementar los shaders que nos dé la gana, pero siempre habrá de existir un Vertex y Fragment shader.
OpenGL antiguamente se encargaba de toda la magia de las transformaciones de tus vértices, actualmente es el programador mediante el VertexShader quien se encarga de estas transformaciones. Veamos un ejemplo:
#version 120
attribute vec3 position;
attribute vec3 color;
attribute vec2 uv;
attribute vec2 lightmap_uv;
uniform mat4 projection;
uniform mat4 camera;
uniform mat4 model;
varying vec3 fragment_color;
varying vec2 fragment_uv;
varying vec2 fragment_lightmap_uv;
void main()
{
gl_Position = projection * camera * model * vec4(position, 1.0);
fragment_color = color;
fragment_uv = uv;
fragment_lightmap_uv = lightmap_uv;
}
Sin entrar en demasiados detalles, podemos observar como calculamos la gl_Position del vértice en el espacio multiplicando por la matriz MPV (model, proyection y view). Podéis repasar las transformaciones del ciclo de vida de un vértice.
Además preparamos la información necesaria para que recoja el FragmentShader, en este caso las UV de la textura y las UV del lightmapping.
Veámos que hace el FragmentShader:
#version 120
#define TEXTURE_ATLAS_W 800
#define TEXTURE_ATLAS_H 800
varying vec3 fragment_color;
varying vec2 fragment_uv; // 0 = u, 1 = v
varying vec2 fragment_lightmap_uv; // 0 = u, 1 = v
uniform sampler2D diffuse_sampler;
uniform sampler2D lightmap_sampler;
void main() {
gl_FragColor = texture2D(diffuse_sampler, fragment_uv) * texture2D(lightmap_sampler, fragment_lightmap_uv);
}
Este shader, es el que determina el color del píxel en pantalla. Se denomina Fragmento a toda la información necesaria para poder renderizar un píxel en su estadio final. En mi caso se puede ver como obtengo el color de la textura y lo multiplico por el color del lightmapping, resultando en gl_FragColor el color final del píxel.
Más adelante profundizaremos en el uso de Shaders. No puedo dejar de recomendar echar un vistazo a https://www.shadertoy.com/ donde existen multitud de shaders para conseguir distintos efectos.
Resumen
Hemos repasado las consideraciones principales a la hora de convertir un render CPU a OpenGL moderno. Con esto conseguiremos un impacto brutal en el rendimiento, imposible de igualar con CPU.
En sucesivos artículos iré detallando los pormenores de la implementación en OpenGL a la vez que seguiré manteniento el render CPU activo.
Actualmente estoy formándome en Vulkan y mi intención es presentar un artículo similar para esta API, sucesora de OpenGL. Hasta la próxima!